



In dit artikel de uitleg hoe het kan dat er over alle onderwerpen rondom Covid-19 op basis van studies en cijfermateriaal zulke tegenovergestelde conclusies worden getrokken. Dat levert grote risico's op als dataverzameling, - analyse en -advies in één hand worden gehouden (RIVM) en men niet transparant is geweest over de gehanteerde modellen.
Lees volledig artikel: Zelfde data, tegenovergestelde conclusies
Zelfde data, tegenovergestelde conclusies
Grote verschillen
Wat me de afgelopen twee jaar vooral opviel, is dat ik over ieder onderzoeksonderwerp tijdens de Coronacrisis onderzoeken tegen kwam, die tot diametraal tegenovergestelde conclusies leidden. Met als gevolg dat je zag dat er, afhankelijk van het standpunt van de betrokkene, een studie werd uitgelicht, die dat standpunt ondersteunde.
Regelmatig als ik naar de bron ging en de verantwoording van de studies bekeek, kon je zien welke problemen de aannames hadden waardoor de basis van de conclusies zeer wankel waren. Ik heb er regelmatig op deze site over geschreven. Dit zijn een aantal voorbeelden:
- De recente grootschalige studie van RIVM medewerkers, waarin net gedaan werd of gevaccineerden en ongevaccineerden in dezelfde mate zich lieten testen met of zonder klachten.
- Manipulatie van data om natuurlijke infectie als bescherming ondergeschikt te maken aan vaccinatie.
- Hoe men oude data gebruikt om conclusies te trekken over nu.
- Door over een lange tijd te rapporteren, toen nog weinig mensen waren gevaccineerd, om zo een overschatting te geven van de opnames van ongevaccineerden maanden later.
En dit artikel zou ellenlang worden als ik buitenlandse studies erbij zou betrekken.
Fascinerende studies
Ik stuitte op een aantal fascinerende studies van een aantal jaren geleden, waardoor je dit proces beter kunt begrijpen. Ook als je weinig van statistiek en data begrijpt. Door deze tweetserie ben ik daarop attent gemaakt en ik wil het graag met jullie delen.
In 2012 publiceerde John Ionnadis (die ook diverse meta-studies heeft uitgevoerd over het onderwerp mortaliteit door Covid-19) een meta-analyse over de relatie tussen kanker en het eten en drinken en dat we nuttigen. Hij vond meer dan 250 studies die daarover data presenteerden. Het betrof ongeveer 40 verschillende soorten eten en drinken.
Van de 9 soorten, waar de meeste studies van gevonden werden, zetten ze de resultaten af in een grafiek. Die is hieronder te zien. Daaruit is goed op te maken hoe gevarieerd en tegenstrijdig de uitkomsten zijn. Rechts van de streep betekent “verhoging van de kans op kanker”, links van de streep “verlaging van de kans op kanker”. Ieder rood puntje is het resultaat van een studie.
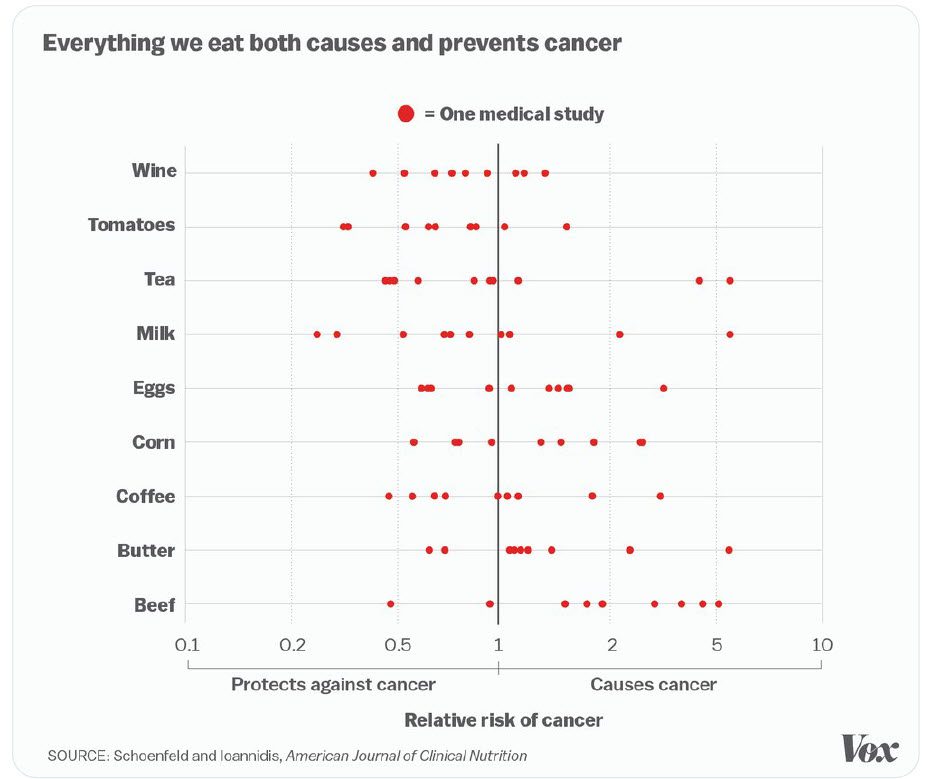
Dus bij wijn zijn er drie studies die aangeven dat het risico op kanker erdoor wordt verhoogd en zes waardoor dat verlaagd wordt.
Tekortkomingen
De auteurs bekijken ieder van die studies en vinden bij nogal wat studies tekortkomingen, waardoor er vraagtekens gezet kunnen worden bij de resultaten. Die hingen samen met de studie-opzet of dat de resultaten niet significant waren door te weinig personen in de studie.
Dit bovenstaande gebruik ik als inleiding voor de volgende studie, die heel leerzaam is. Want daarbij werd een heel belangwekkend experiment uitgevoerd. Aan 29 verschillende onderzoeksteams werd dezelfde dataset verstrekt met de vraag om een analyse uit te voeren en vervolgens hun conclusies te trekken. En wat bleek: er waren grote verschillen in de uitkomsten!
Men had een uitgebreide data-set gemaakt met informatie over rode kaarten gegeven aan voetballers in Frankrijk, Duitsland, Engeland en Spanje gedurende het seizoen 2012-2013. Van de ongeveer 2.000 voetballers werden demografische gegevens verzameld en ook de informatie over de meer dan 3.000 scheidsrechters die zij in hun hele professionele carrière hadden gehad. En de onderzoeksvraag was: “hebben donkere spelers meer kans om een rode kaart te krijgen?“.
Er was een grote verscheidenheid aan uitkomsten van die 29 onderzoeksteams. Twintig kwamen met een significant resultaat dat dit wel het geval was en negen niet. Het gemiddelde van de studies lag rond 1,35 keer een grotere kans, maar er was ook een uitkomst met een kans, die bijna drie keer zo groot was en twee studies kwamen met een uitkomst dat de kans iets kleiner was dan 1.
Dit zijn dus uitkomsten met exact dezelfde data.
Hoe kan dat?
Het is echt heel leerzaam te begrijpen waar de verschillen vandaan komen.
Dat is namelijk heel eenvoudig uit te leggen.
De simpelste manier om een conclusie te trekken is:
- Van de donkere spelers heeft X% een rode kaart gekregen en van de overige spelers Y%. Als X% groter is dan Y%, dan krijgen donkere spelers vaker een rode kaart. En het verschil is X gedeeld door Y.
Maar spelers in de achterhoede krijgen vaker een rode kaart. En als donkere spelers vaker in de achterhoede spelen, dan verhoogt dat dus hun kans op een rode kaart.
Daarnaast is het een bekende zaak dat bepaalde scheidsrechters vaker rode kaarten geven dan andere scheidsrechters. Dus als donkere spelers vaker deze scheidsrechters hebben gehad, dan verhoogt dat hun kans op een rode kaart.
Om dan dus de analyse echt goed uit te voeren, moet je maatregelen nemen om het effect van die factoren te neutraliseren.
Nu waren in de data nog meerdere factoren meegenomen, zoals leeftijd van de speler, hoe lang ze al actief waren in het betaald voetbal, op welke plaats het team stond in de competitie, of het een uit- of thuiswedstrijd was, etc.
De onderzoekers moesten bepalen welke factoren ze wel meenamen in hun analyse (daar zijn statistische methodes voor) en hoe met welke benadering ze hun analyse uitvoerden.
De 29 teams bleken 21 verschillende aanpakken gekozen te hebben!
De gemiddelde uitkomst was dus dat de kans 1,35 keer zo groot was, maar de hoogste uitkomst was dus bijna 3 keer en de laagste minder dan 1 keer. In 20 gevallen werd aangegeven dat het een significant verschil was (niet op toeval berustte) en in 9 gevallen dat het resultaat niet significant was (wel op toeval berustte).
Ruim de helft van de studies kwam met een significant resultaat dat ergens tussen de 1,3 en 1,4 lag.
Wat betekent dit voor de Covid-data en -studies?
Het bovenstaande laat zien dat de wijze waarop de studie wordt uitgevoerd grote gevolgen kan hebben voor de uitkomsten. Bij Covid weten we dat er grote verschillen zijn tussen ouderen en jongeren. Dat de gezondheidssituatie van een persoon een belangrijke rol kan spelen. Dat er nogal wat schort aan de data-verzameling. En dat er ook nogal wat keuzes gemaakt moeten worden t.a.v. de definities t.a.v. het gevaccineerd zijn of niet. Hoe het testbeleid is in een bepaalde periode.
Bij ziekenhuisopnames en sterfte is er de vraag of dat kwam door Covid of met Covid. Bij gezondheidsproblemen, of sterfte kort na vaccinatie en of die sterfte al dan niet iets met die vaccinatie te maken heeft.
Dus het is niet zo dat als wetenschappers met een studie komen, je dan kunt zeggen: “De wetenschap heeft aangetoond dat….”.
Problemen met het goed uitvoeren van studies waren er altijd. En het verzamelen van goede data is niet altijd eenvoudig.
Maar het grote verschil in de afgelopen twee jaar was dat de data en studies ook door wetenschappers gebruikt werden om dat wat ze vonden moest gebeuren te onderbouwen. Modellen werden gemaakt met daarin cijfermatige aannames op basis van bepaalde studies.
Echter, de transparantie was beperkt. In feite lag alles in handen van één organisatie en daarbij weer bij een beperkt aantal personen. Te weinig is er gedaan aan het betrekken van externe deskundigen om dat proces te verbeteren en ervoor te zorgen dat de conclusies zo goed mogelijk waren.
Dat heeft er trouwens mede voor gezorgd dat ook onder degenen die volledig andere opvattingen hadden over de belangrijkste onderwerpen, zoals de maatregelen en vaccinatie, ook regelmatig conclusies trokken op basis van materiaal, waar ik ook gekromde tenen van kreeg.
Speelbal
Daarmee werden de data en de onderzoeken de speelbal van een soort actievoerders, die zich vermomden als wetenschappers.
Dat heeft de wetenschap geen goed gedaan om het eufemistisch uit te drukken. En het imago van modellen en modelleurs is fors gedaald.
Er zal veel dienen te gebeuren in de komende tijd om deze schade te herstellen en te voorkomen dat zoiets weer gaat gebeuren. Zet de dataverzameling en -interpretatie compleet los van de adviseurs en beleidsmakers. Maak het proces compleet transparant en betrek er experts bij van verschillend pluimage.
Want anders blijven we, roepende dat de wetenschap leidend is, die wetenschap juist misbruiken. Terwijl het zoveel beter kan en moet.
Help onze site met het blijven brengen van artikelen om betere informatie te verzamelen en betere besluiten te laten nemen. Klik hier voor af en toe een (kleine) donatie.
U heeft zojuist gelezen: Zelfde data, tegenovergestelde conclusies.
Volg Maurice de Hond op Twitter | Facebook | LinkedIn | YouTube.



